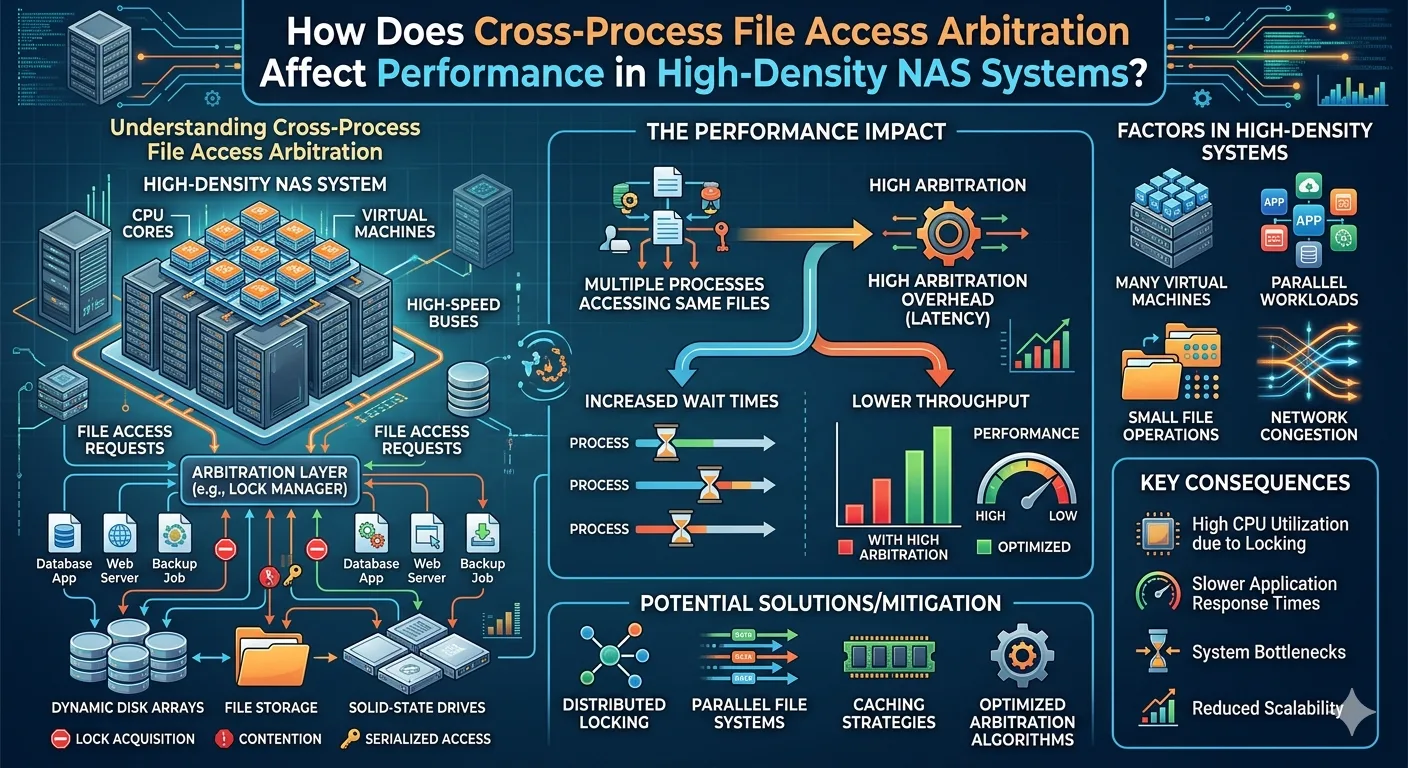
Modern enterprise infrastructure relies heavily on shared storage architectures to support concurrent workloads, virtualization, and massive datasets. As organizations consolidate their data, high-density storage environments become the standard. Within these architectures, multiple clients, applications, and background processes frequently attempt to read or modify the exact same files simultaneously. Ensuring data integrity under these conditions requires strict governance over who gets to read or write data at any given microsecond.
This governance is handled through cross-process file access arbitration. At its core, arbitration is the algorithmic and network-level protocol used to manage concurrent access requests, utilizing mechanisms like file locking, semaphores, and metadata updates. While absolutely critical for preventing data corruption, the computational and network overhead required to mediate these competing requests can significantly impact storage performance.
Understanding the mechanics of file access arbitration is essential for IT architects and storage engineers. When evaluating high-density environments, recognizing how arbitration algorithms interact with network protocols reveals the root causes of latency spikes and throughput degradation. This article examines the technical mechanics of cross-process arbitration, its specific impact on IOPS and latency, and how modern architectures attempt to mitigate these performance bottlenecks.
The Mechanics of File Access Arbitration
Cross-process file access arbitration operates on the principle of mutual exclusion. When a process requests modification rights to a file, the storage controller or file system must grant a lock. This lock prevents other processes from writing to the file until the initial operation concludes.
In traditional enterprise environments, locking mechanisms are handled centrally. Network protocols such as Server Message Block (SMB) and Network File System (NFS) utilize strict locking protocols to maintain consistency. When a client requests an opportunistic lock (oplock) or a byte-range lock, the storage controller registers this state in its active memory.
However, high-density Nas Systems process millions of these requests per second. The storage controller must actively maintain a state table for every open file and every associated lock. As the number of concurrent processes increases, the CPU cycles dedicated to traversing and updating these state tables scale linearly. Eventually, the hardware reaches a saturation point where the storage controller spends more computational resources managing locks than serving actual data payloads.
Lock Contention and Latency Spikes
Performance degradation primarily manifests as lock contention. When Process A holds a lock and Process B requests access, Process B must wait. In high-density environments, this waiting period translates to application-level latency.
The issue compounds when network latency is introduced. In standard Nas Systems, the time required to grant a lock, acknowledge the lock over the network, perform the I/O operation, and release the lock is dictated by network speed. If packet loss or network congestion occurs, locks are held longer than necessary. This creates a queuing effect, causing a backlog of pending I/O operations that can stall entirely independent applications sharing the same storage infrastructure.
Architectural Shifts: Scale out nas Storage
To overcome the controller bottleneck inherent in traditional unified storage, enterprises frequently migrate to Scale out nas Storage. Unlike scale-up architectures that rely on a dual-controller high-availability pair, a scale-out architecture distributes the file system across a cluster of independent nodes.
While Scale out nas Storage dramatically increases aggregate throughput and capacity, it introduces a new layer of complexity to file access arbitration: the distributed lock manager (DLM). Because any node in the cluster can service a client request, the cluster must ensure that Node 1 does not grant a write lock to a file that Node 4 is currently modifying.
Distributed Arbitration Overhead
In Scale out nas Storage environments, arbitration is no longer a localized memory operation. It requires east-west traffic across the cluster's backend network. When a client requests access, the receiving node must query the DLM to verify the lock state.
This distributed coordination introduces physical network latency into the arbitration process. To maintain high performance, Scale out nas Storage vendors utilize high-speed, low-latency interconnects—such as InfiniBand or 100GbE with RDMA (Remote Direct Memory Access). RDMA allows nodes to read lock states directly from the memory of other nodes without interrupting their CPUs. Despite these hardware accelerations, distributed file access arbitration remains a highly latency-sensitive operation. If the backend cluster network experiences microbursts or congestion, the arbitration process slows down, directly degrading the front-end client performance.
Mitigating Arbitration Impact on Performance
Storage engineers must employ specific strategies to minimize the performance tax of cross-process arbitration in high-density environments. Properly configuring both the clients and the storage backend ensures that data integrity mechanisms do not strangle application performance.
Byte-Range Locking and Granularity
One primary method for reducing lock contention is leveraging byte-range locking rather than whole-file locking. Databases and virtualization platforms frequently use large container files. If a process locks the entire 50GB virtual disk file to update a single 4KB block, all other operations halt.
Advanced Nas Systems support granular byte-range locking, allowing the system to lock only the specific blocks being modified. This permits highly concurrent access to large files, drastically reducing wait times. Ensuring that client applications and the underlying file system are configured to support byte-range locking is critical for database and virtualized workloads.
Lock Leases and Delegation
Modern network file protocols implement lock leases and delegation to reduce network chattiness. Instead of requesting permission for every single read or write, a client can request a lease for a file.
If no other clients are requesting the data, the storage system delegates authority to the client. The client can then cache the file locally, perform multiple read/write operations, and manage its own locks without communicating with the central storage controller. If a second client requests the file, the storage system recalls the delegation. In Scale out nas Storage clusters, this delegation dramatically reduces the east-west arbitration traffic, freeing up cluster resources and minimizing application latency.
Optimizing Your High-Density Infrastructure
Addressing the performance impacts of cross-process file access arbitration requires a systematic approach to infrastructure design. Hardware specifications alone cannot mask the overhead of poorly optimized locking protocols.
To ensure optimal performance, storage administrators should audit their current workloads to identify highly concurrent files and directories. Evaluate whether your current Nas Systems are properly handling oplocks and delegations. For environments experiencing severe controller bottlenecks, transitioning to Scale out nas Storage equipped with RDMA backends can distribute the arbitration load effectively. By aligning your application locking behaviors with your storage architecture's capabilities, you can maintain strict data integrity without sacrificing the high-speed performance modern enterprises demand.


